
Tanzu Services Deployment Guide
Benefits of Running Tanzu Kubernetes Grid Managed Service
VMware Cloud on AWS enables your IT and Operations teams to add value to your investments in AWS by extending your on-premises VMware vSphere environments to the AWS cloud. VMware Cloud on AWS is an integrated cloud offering jointly developed by Amazon Web Services (AWS) and VMware. It is optimized to run on dedicated, elastic, bare-metal Amazon Elastic Compute Cloud (Amazon EC2) infrastructure and is supported by VMware and its partners. To learn more about VMware Cloud on AWS, see VMware Cloud on AWS Documentation.
VMware Cloud on AWS enables the following:
- Cloud Migrations
- Data Center Extension
- Disaster Recovery
- Modern Application Development
By running VMware Tanzu within the same infrastructure as the general VM workloads enabled by the first three use cases, organizations can immediately start their modern application development strategy without incurring additional costs. For example, you can use SDDC spare capacity to run Tanzu Kubernetes Grid to enable next-generation application modernization, or compute power not used by disaster recovery can be used for Tanzu Kubernetes Grid clusters.
Tanzu Kubernetes Grid Managed Service Architecture
This reference architecture details how to use Tanzu services in a VMware Cloud on AWS SDDC. The Tanzu Kubernetes Grid Managed (TKG) managed service used in this architecture deploys a pair of vSphere Namespaces and some Tanzu Kubernetes clusters. Tanzu Mission Control (TMC) deploys Fluent Bit extensions for log collection and aggregation with vRealize Log Insight Cloud. TMC can also deploy Tanzu Observability to monitor Kubernetes metrics at scale. TMC configures containers and persistent storage backups through Velero using Amazon Web Services S3 as a durable object storage location.
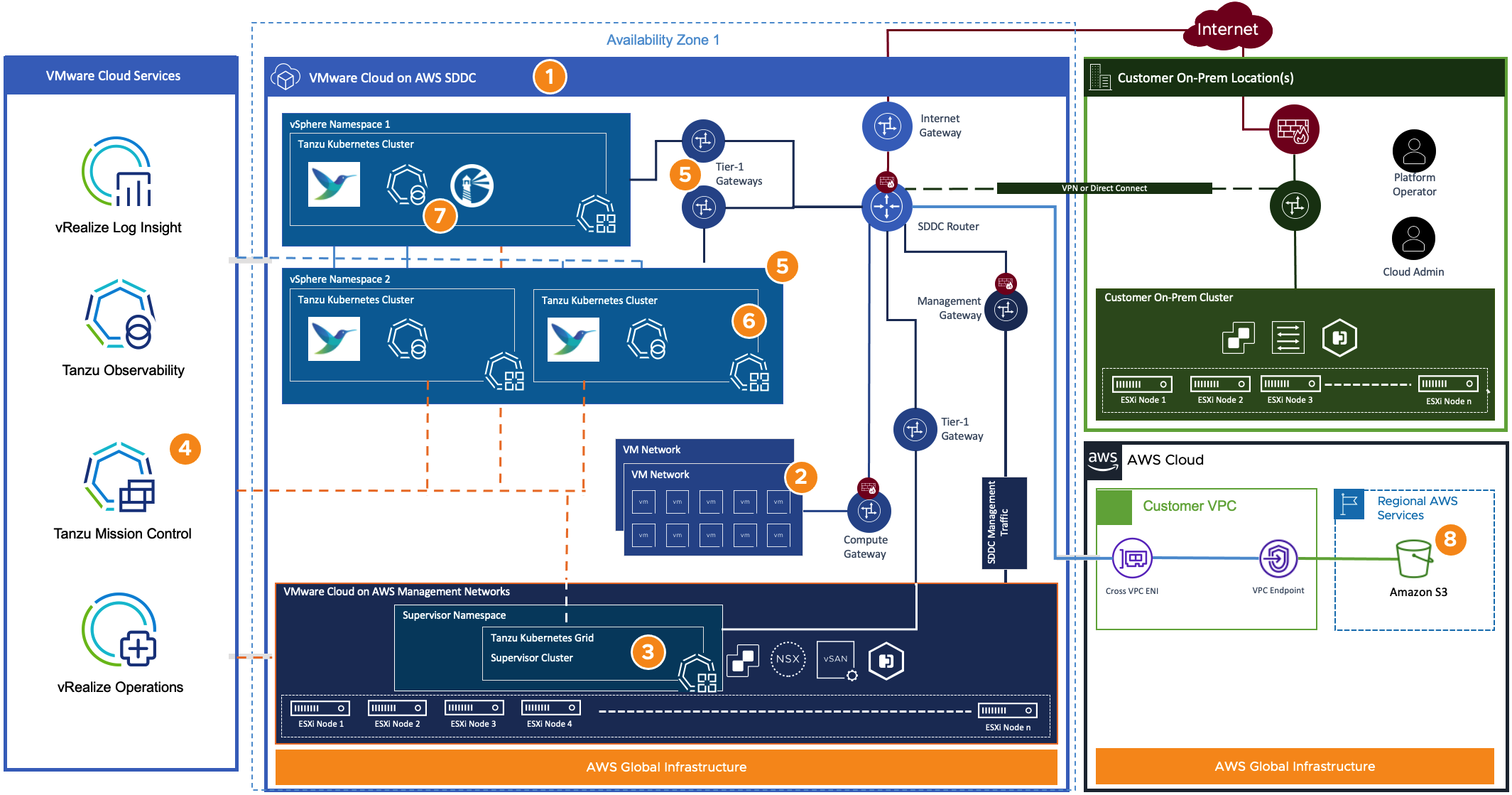
- Deploy the VMware Cloud on AWS SDDC in the desired region and availability zone.
- Virtual machines run within the same SDDC on their own network segments connected to the VMware Cloud Compute Gateway and protected by firewall rules. These networks are typical but not required for the Tanzu Kubernetes Grid Service.
- The cloud administrator activates the Tanzu Kubernetes Grid service, deploying the supervisor cluster into the VMware-managed network segments. This network placement is comparable to deploying vCenter and NSX appliances within VMware Cloud on AWS SDDC.
- After successfully activating the TKG service, register the TKG Supervisor cluster as a management cluster within Tanzu Mission Control.
- The cloud administrator creates vSphere Namespaces from within the vCenter’s vSphere Client. These vSphere Namespaces provide resource and tenant isolation capabilities. The cloud administrator assigns resource limits for CPU, memory, and storage then enables access to these resources for users via vCenter Single Sign-On.Each vSphere Namespace provisioned creates a new Tier-1 Gateway and connects a new network segment with the SDDC router. The vSphere Namespace network segments come from the CIDR ranges provided during the TKG activation process.
- Platform operators deploy new Tanzu Kubernetes clusters into their assigned vSphere Namespaces through the kubectl CLI or Tanzu Mission Control.
- The platform operators can use Tanzu Mission Control to set Kubernetes Polices for their clusters and use the TMC Catalog to deploy tools such as Fluent Bit configured to work with vRealize Log Insight Cloud for log aggregation, Tanzu Observability for capturing performance monitoring and metrics, or Harbor Image Registry for OCI compliant images.
- Platform operators can configure an Amazon S3 storage location for a backup destination configured through Tanzu Mission Control.
VMware Cloud on AWS Organization and SDDC Considerations
The Tanzu Kubernetes Grid managed service runs within a VMware Cloud on AWS Software-Defined Data Center (SDDC). These SDDCs get deployed within a VMware Organization that includes both soft and hard limits when deploying cloud resources. The sections below will help identify the organization and SDDC considerations when designing your VMware Cloud.
Cloud Services Organization Considerations
Cloud administrators must deploy a Software-Defined Data Center within a VMware Organization. The Organization is a VMware Cloud construct used to assign VMware Services to a set of billed users. Consider organizational considerations when building a VMware Cloud on AWS environment to ensure proper billing, multi-tenancy, and sizing for your company. Tanzu services require a VMware Organization and an SDDC to use Tanzu Kubernetes Grid functionality, so plan your Organization and SDDC deployments accordingly.
Billing Considerations – Each VMware Organization consists of its own set of resources billed to a customer. If users must have different billing requirements by teams, multiple organizations may need to be created and assigned appropriately to ensure that cloud costs are not shared between groups.
Multi-Tenancy Considerations – VMware Organizations have their own roles and permissions, which are used to assign access to VMware services. You can configure a VMware Organization with an identity provider to allow customers to use their existing authentication mechanisms with VMware Cloud. In some cases, users need to have more substantial isolation between teams for contractual or other security purposes. Cloud administrators can create additional VMware Organizations to link identity providers to different Organizations and provide stronger isolation of services between teams or groups.
Sizing Considerations – VMware Cloud services have configuration maximums that cannot be exceeded. VMware Cloud administrators may provision additional Organizations if they are approaching these configuration limits. For more information, review the VMware Cloud on AWS configuration maximums.
For help with sizing your VMware Cloud try the VMware Cloud on AWS Sizer.
Software-Defined Data Center Considerations
Cloud administrators must deploy a VMware Software-Defined Data Center before activating the Tanzu Kubernetes Grid managed service. vCenter and the NSX components needed to manage your vSphere clusters are deployed into this SDDC and must be sized appropriately for your workloads. Each VMware SDDC has its own availability and sizing considerations that should be applied when designing an SDDC layout.
VMware Cloud on AWS uses several virtual appliances as a control plane for the SDDC. Cloud administrators must size these appliances to handle the number of objects used concurrently within the SDDC. VMware Cloud on AWS SDDC appliances come in two sizes: Large and Medium.
The size of the appliances determines how many objects can be managed within the SDDC. You should carefully review configuration maximums for the appliances before deploying the SDDC.
See the VMware Configuration Maximums site for more information and guidance.
The Tanzu Kubernetes Grid Supervisor cluster is a specialized Kubernetes cluster running components of ClusterAPI to deploy additional Tanzu Kubernetes clusters. The Supervisor cluster is a critical component of the management of the Tanzu Kubernetes clusters and is deployed with high availability in mind. TKG Supervisor cluster nodes are deployed on different physical hosts to prevent a service outage from a physical host failure. For this reason, you must have an SDDC with a minimum of three ESXi hosts to activate the Tanzu Kubernetes Grid Service.
Connected VPC Considerations
Every VMware Cloud on AWS SDDC has a low latency connection with a connected Amazon Web Services Virtual Private Cloud (VPC) to connect VMware Cloud resources with AWS services. Each VMware SDDC can be connected to one VPC at a time through this low latency ENI connection.
This connected VPC is a great way to access AWS native services over a non-public, low-latency connection. However, suppose you need to connect multiple AWS VPCs to your SDDC. In that case, Cloud administrators should use a transit gateway, VPN, Direct Connect, or other methods to connect to additional AWS VPCs.
If multiple connected VPCs are required, additional VMware Cloud on AWS SDDCs can be deployed and connected to different AWS VPCs in a 1:1 relationship.
Availability and Disaster Recovery Considerations
Handling failures is critical for any platform. Platform operators should deploy Tanzu Kubernetes clusters with the possibility of failure in mind. The sections below contain considerations for improving the availability of Tanzu Kubernetes workloads.
VMware Cloud on AWS utilizes Amazon Availability zones (AZs) when deploying an SDDC. VMware offers two deployment options with an SDDC:
Single AZ Deployment Type – The Single AZ deployment type will place all the SDDC’s ESXi hosts into a single Amazon Availability Zone. In this mode, a physical host failure is handled by vSphere HA, and VMware Cloud provisions a new host to replace it. However, an entire Amazon Availability Zone outage could prevent the cluster from operating.
Stretched Cluster Deployment Type – The Stretched Cluster deployment type will split the deployment of ESXi hosts evenly across a pair of Amazon AZs. In this scenario, losing an entire Amazon AZ would mean that vSphere HA would restart the virtual machines from the failed hosts onto the remaining hosts in the second AZ.
NOTE: The Tanzu Kubernetes Grid Supervisor cluster cannot currently be deployed in a stretched cluster SDDC deployment. Please use a Single AZ deployment when creating your SDDC.
Backups
Many container-based workloads do not require backups due to their transient nature and a lack of need for persistent storage. In these cases, the quickest way to restore services after a failure is to re-deploy the application through its source code repository. For all other applications, cloud administrators should ensure that persistent data is backed up to protect it from data loss in the event of failure.

VMware recommends the use of project Velero. Velero is an open-source tool to backup, restore, and migrate Kubernetes resources. Using Velero, platform operators can backup pods, persistent volumes, or entire Kubernetes namespaces as a point-in-time backup or on a schedule and store the backups in an S3 compliant object store like Amazon S3.
Platform operators can deploy Velero through the Tanzu Kubernetes Grid extensions or the Tanzu Mission Control Interface. Amazon S3 storage can be used for the Velero backups over the VMware Cloud on AWS ENI connection with AWS.
Production systems must ensure that cloud providers’ wide-scale outages do not affect critical services. A disaster recovery plan should be in place for critical systems to account for a cloud outage.
The Tanzu Kubernetes Grid managed service only operates within a single AWS Availability Zone, so the outage of this specific AZ would also lead to an outage of TKG. Consider the disaster recovery methodologies below.
Active/Active Clouds – In an active/active cloud scenario, the workloads are live and operational in two separate clouds. These clouds usually leverage a global load balancer that can direct traffic to either cloud based on the business's needs. This type of methodology requires the building and maintaining two separate cloud environments either with the same cloud vendor or different cloud vendors. Applications are deployed to both environments and kept in sync so that if either cloud were to become offline, the resources in the second cloud would continue running and prevent a service outage while the offline cloud issue is resolved. This scenario would best fit organizations that can’t absorb extended outages or data loss but comes at the highest price.
Active/Passive Clouds – Similar to an active/active cloud, active/passive clouds still require two sets of resources. In an active/passive setup, one cloud acts as a primary instance and services all requests until there is an outage, at which point the passive cloud becomes active. This pattern may require minimal hands-on work to bring the passive cloud to a ready state before services are restored. This methodology is often called a warm standby site. Passive clouds are helpful to keep costs low and provide a relatively quick recovery time in the event of a declared outage.
Backup/Restore – Not all businesses have a second cloud ready to be used for a disaster recovery event. Sometimes having the critical data backed up and available is enough to protect the company. In these scenarios, a failed cloud could mean deploying a new cloud and re-attaching or restoring data into this cloud. This methodology would have a lower cost than having secondary clouds ready to go but would also take much longer to restore services in an outage.
Customers should choose the disaster recovery scenario that best fits their risk profile.
Tanzu Kubernetes Grid Managed Service Components
The Tanzu Kubernetes Grid managed service provided through VMware Cloud on AWS consists of multiple components for multi-cluster Kubernetes management. The sections below focus on the individual elements needed to understand the architecture and customers' responsibilities with these components.
Supervisor Cluster
The Kubernetes cluster created when activating the TKG service is called a Supervisor Cluster. It runs on top of an SDDC layer that consists of ESXi for compute, NSX-T for networking, and vSAN for a shared storage solution. After a cloud administrator activates the Supervisor Cluster, they will create vSphere Namespaces, which assign resources to platform operators. As a DevOps engineer, you can deploy Kubernetes Pods running inside Tanzu Kubernetes clusters.

The Tanzu Kubernetes Grid activation process deploys a Tanzu Kubernetes Grid Supervisor Cluster into your VMware SDDC. This supervisor cluster contains the ClusterAPI components needed to deploy Tanzu Kubernetes clusters within vSphere Namespaces. It runs on top of an SDDC layer that consists of ESXi for compute, NSX-T Data Center for networking, and vSAN for a shared storage solution.
The Supervisor Cluster within VMware Cloud on AWS consists of several components:
Kubernetes control plane VM. Three Kubernetes control plane VMs are created on the hosts that are part of the Supervisor Cluster. The three-control plane VMs are load-balanced as each has its own IP address. Additionally, a floating IP address is assigned to one of the VMs. vSphere DRS determines the exact placement of the control plane VMs on the ESXi hosts and migrates them when needed.
- The Cluster API and VMware Tanzu™ Kubernetes Grid™ Service are modules that run on the Supervisor Cluster and enable the provisioning and management of Tanzu Kubernetes clusters. The Virtual Machine Service module is responsible for deploying and running stand-alone VMs and VMs that makeup Tanzu Kubernetes clusters.
Tanzu Kubernetes Clusters
Tanzu Kubernetes Clusters (TKCs) are Cloud Native Computing Foundation (CNCF) conformant Kubernetes clusters that have been provisioned through Tanzu Kubernetes Grid. Platform operators will deploy business workloads into these clusters and use the Tanzu Supervisor cluster to manage their lifecycle.
The components that run in a Tanzu Kubernetes cluster span four areas: Authentication and authorization, storage integration, pod networking, and load balancing.
- Authentication webhook: A webhook running as a pod inside the cluster to validate user authentication tokens.
- Container Storage Interface Plugin: A Paravirtual CSI plug-in that integrates with Cloud Native Storage (CNS) through the Supervisor Cluster.
- Container Network Interface Plug-in: A CNI plug-in that provides pod networking.
- Cloud Provider Implementation: Supports creating Kubernetes load balancer services.
Tanzu Kubernetes Grid Managed Service - Storage
Tanzu Kubernetes Grid clusters deployed on VMware Cloud on AWS can take advantage of the shared VMware vSAN datastore included with the purchase of VMware Cloud hosts. Platform operators can use this datastore for control plane VMs and persistent storage volumes running within the Tanzu Kubernetes clusters.
vSphere Storage Administration
Cloud administrators are responsible for allocating resources to users through a vSphere Namespace. One of these resource allocations is for storage access.
When allocating storage through a vSphere Namespace, cloud administrators need to provide a VM Storage Policy. vSAN storage policies define storage requirements for your virtual machines. These policies determine how the storage objects are provisioned and allocated within the datastore to guarantee the required level of service.
For best results, consider creating and using your own VM storage policies, even if the policy requirements are the same as those defined in the default storage policy. In some cases, when you scale up a cluster, you must modify the default storage policy to maintain compliance with the requirements of the Service Level Agreement for VMware Cloud on AWS.
After identifying the appropriate vSAN storage policy to match the workload requirements, cloud administrators will add the storage policy to the namespace storage resource assignment.

Once storage policies are associated with a vSphere Namespace, platform operators will be able to create Kubernetes Storage Classes based on the storage policy.
Kubernetes Storage Usage
Platform operators use storage classes to create persistent volumes for Kubernetes pods dynamically. When a storage policy is used during cluster creation, the TKG service creates storage classes with a name corresponding to the vSAN Storage policy in the Tanzu Kubernetes clusters.
![]()
Storage Classes are a native Kubernetes construct and should be familiar to platform operators familiar with Kubernetes administration. As pods begin using persistent volumes to store data, container volumes will be visible within the vCenter Console.
![]()

Tanzu Kubernetes Grid Managed Service - Networking
The Tanzu Kubernetes Grid Managed service depends on the NSX-T infrastructure used to connect elements of the VMware Cloud. The sections below focus on sizing decisions Cloud Architects are faced with when creating SDDCs. The sections below also explain traffic patterns related to Tanzu Kubernetes clusters.
CIDR Sizing
A common method for allocating IP addresses is to use Classless Inter-domain Routing (CIDR). These CIDR ranges are notated as an IP address and mask such as 192.168.0.0/24 which would include the IP addresses 192.168.0.0 – 192.168.0.254. Cloud administrators will need to supply four distinct CIDR ranges to activate the Tanzu Kubernetes Grid Managed Service. Each of these CIDR ranges has a specific purpose laid out below.
The Tanzu Supervisor Cluster uses the Service CIDR as a pool of addresses available for Kubernetes services. The TKG Supervisor cluster is a specialized Kubernetes cluster and requires the same type of networking information that any Kubernetes cluster would need. Kubernetes service IP addresses within the Supervisor Cluster are allocated from this service CIDR. Typically, the default CIDR range can be used here as these addresses are only used within the TKG Supervisor cluster for communication with pods such as the Kubernetes API server.
When a cloud administrator creates a new vSphere Namespace, a new Tier-1 gateway is deployed, and a new network segment is created. Tanzu Kubernetes cluster nodes will be attached to these namespace segments, and each node requires an IP Address. When sizing your Namespace CIDR for TKG Activation, ensure that your CIDR range is large enough to accommodate the number of Tanzu Kubernetes nodes deployed. Note: Tanzu services requires CIDR range of /23 or higher.

Ingress CIDR
The namespace Tier-1 router will create a Load Balancer and a virtual IP (VIP) address to be used to access the Tanzu Kubernetes clusters (TKCs). The VIP address used by the load balancer comes from the ingress CIDR configured during the TKG activation steps. When an admin creates a new Tanzu Kubernetes cluster, a Load Balancer gets produced in the Namespace Tier-1 router. An address is pulled from the pool of Ingress addresses and then assigned as the virtual IP address for this load balancer. Platform operators connect to the Kubernetes API server through this address. Another VIP is created when a new Kubernetes service of the type LoadBalancer is deployed. The TKC virtual machine IP addresses are added to the virtual load balancer as targets for use with Kubernetes applications.
When sizing the Ingress CIDR, account for the following IP Addresses pulled from the Ingress CIDR range.
Kubernetes Cluster API Server – Each TKC deployed will have an API server to communicate with the Kubernetes control plane. This IP Address is pulled from the Ingress CIDR range.
Kubernetes Service of Type Load Balancer – As platform operators create new Kubernetes Services of type “LoadBalancer,” a new virtual service is formed on the Tier-1 routers, and a virtual IP (VIP) address is assigned to this virtual service. This VIP is pulled from the Ingress CIDR range used to activate the Tanzu Kubernetes Grid Managed Service.
Note: It is important to identify the number of Ingress IP Addresses needed when designing your SDDC. There are limits to the number of virtual services created within a single SDDC. See the section focusing on SDDC Considerations for more details.
Egress CIDR
A source network address translation (SNAT) is created on the namespace Tier-1 gateway to provide access to resources outside the namespace. As traffic from any TKC node leaves the cluster, the source IP Address is translated into an egress IP address before leaving the Tier-1 gateway.
This NAT rule is created for each Tier-1 gateway within the SDDC, including one for the Supervisor Cluster. When sizing the Egress CIDR, ensure that you have one IP Address to account for every namespace created, plus one for the Supervisor Cluster.

Ingress
In this context, Ingress refers to getting network traffic to the Tanzu Kubernetes cluster from a client. Clients may need to access the Kubernetes API server or any Kubernetes services of the type “LoadBalancer.”
Each Kubernetes service of the type “LoadBalancer” will get its own virtual service within the vSphere Namespace’s Tier-1 gateway. This service includes a virtual IP (VIP) address obtained from the Ingress CIDR range used during activation.

Local Access
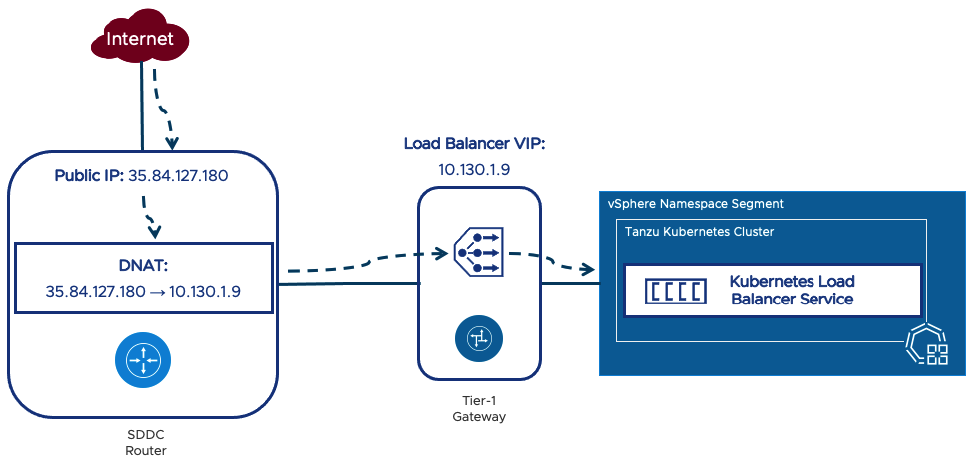
VMware Cloud on AWS automatically creates and configures Load Balancers and virtual servers for any Kubernetes service of type “LoadBalancer,” including the Kubernetes API. The NSX-T container plug-in (NCP) is deployed on every Tanzu Kubernetes cluster within VMC and is responsible for creating NSX Load Balancers. When a new service of the type “LoadBalancer” service is requested, NCP provisions the NSX load balancer/ virtual service and connects them to the Tanzu Kubernetes cluster through a node port.

When access to the Tanzu Kubernetes cluster should be made public, a platform operator will deploy a Kubernetes service of type “LoadBalancer” as described in the Local Access section of this document. Once completed, a cloud administrator can create a public IP Address through the VMC console and create a DNAT rule that translates this public address to the Load Balancer VIP created through the NSX-T Container Plugin.
Connected VPC
VMware Cloud on AWS SDDCs are attached to a customer’s AWS Virtual Private Cloud through a low latency ENI connection. This network connection can be used to access AWS Native services such as Amazon S3, Amazon EC2, or Amazon RDS.
This connected VPC can be used with VMware Cloud on AWS resources, such as Tanzu Kubernetes clusters and virtual machines, to extend their functionality without traversing the public Internet. For example, Velero can be used to transfer backup data to Amazon S3 over this ENI instead of sending that traffic to S3 over the public Internet. Utilizing the ENI instead of the Internet can reduce the cloud network costs associated with public Internet traffic and keep it in a private network.

The following additional benefits are enabled by the Elastic Network Interface that connects the VMware Cloud on AWS SDDC to the AWS services within the Amazon VPC:
- Enable developers to modernize existing enterprise apps with AWS cloud capabilities and services.
- Integrate modern application tools and frameworks to develop next-generation applications.
- Remove egress charges as all traffic is internal to the Amazon availability zone.
Firewall Rules
VMware Cloud on AWS uses gateway firewalls to prevent access between network segments. These firewalls have a default deny rule that blocks all traffic unless specifically allowed.
To operate and manage Tanzu Kubernetes Grid consider opening the firewall rules below on the Compute Gateway as found in the Tanzu services reference architecture.
|
Source |
Destination |
Protocol:Port |
Uplink |
|
Tanzu Egress CIDR |
Internet* |
HTTPS |
Internet Uplink |
|
Tanzu Egress CIDR |
Customer Image Registry |
HTTPS |
Uplink Associated with Image Registry |
|
Customer’s Application Clients |
Tanzu Ingress CIDR |
HTTP/HTTPS |
Uplink Associated with Clients |
|
Any |
Customer’s DNS Servers |
UDP 53 (DNS) |
Uplink Associated with DNS Server |
|
Tanzu Egress CIDR |
Customer VPC CIDR |
Service Specific Ports |
Connected VPC |
*Outbound Internet access is required to manage Tanzu Kubernetes Grid with Tanzu Mission Control. If using a proxy for outbound access, this destination can be set to the *.tmc.cloud.vmware.com address instead of the Internet.
Identity and Access Management
Two critical aspects of securing a Kubernetes cluster are verifying the users’ identity (authentication) and assigning them the appropriate permissions (authorization).
Authentication and Authorization
As a vSphere administrator, you need privileges to configure a Supervisor Cluster and manage namespaces. You define permissions on namespaces to determine which platform operators can access them. As a platform operator, you authenticate with the Supervisor Cluster using your vCenter Single Sign-On credentials and can access only the namespaces for which you have permissions.
The Tanzu Kubernetes Grid service uses vCenter Single Sign-On (SSO) to authenticate users with the configured identity provider(s). vSphere administrators authenticate through the vCenter UI or API, and platform operators use the Kubernetes CLI tools for vSphere to authenticate to the Tanzu Kubernetes clusters. The Kubernetes CLI tools redirect requests to the vCenter SSO to obtain a session token for use with the clusters. This token has a default expiration of 10 hours before a session must be re-authenticated.
Platform operators can use the identity federation configured with the Organization as an identity source for Tanzu Mission Control. Users authenticated with TMC can be mapped to either pre-built or custom roles for Kubernetes clusters. Operators can assign policies to the Tanzu Kubernetes clusters through TMC and then obtain a KUBECONFIG file through the console.
Tanzu Mission Control Integration
Tanzu Mission Control is a centralized management platform for consistently operating and securing your Kubernetes infrastructure and modern applications across multiple teams and clouds. It provides operators with a single control point to give developers the independence to drive the business forward while enabling consistent management and operations across environments for increased security and governance.
Cluster Lifecycle Management
Tanzu Mission Control can be used to manage the lifecycle of Tanzu Kubernetes clusters. The Tanzu Kubernetes Grid Supervisor Cluster can be registered within Tanzu Mission Control as a specialized management cluster. After registration, platform operators use Tanzu Mission Control to deploy Tanzu Kubernetes clusters within their vSphere Namespaces from this centralized portal. Through the TMC user interface, platform operators can perform lifecycle tasks such as deploying new clusters, scaling existing clusters, upgrading clusters, and deleting clusters.
Policy-Driven Cluster Management
Tanzu Mission Control allows creating policies of various types to manage the operation and security posture of your Kubernetes clusters and other organizational objects. Policies provide a set of rules that govern your company and all the objects it contains. The policy types available in Tanzu Mission Control include the following:
- Access Policy: Access policies allow predefined roles to specify which identities (individuals and groups) have what level of access to a given resource. For more information, see Access Control
- Image Registry Policy: Image registry policies allow to specify the source registries from which an image can be pulled.
- Network Policy: Network policies allow you to use pre-configured templates to define how pods communicate with each other and other network endpoints.
- Quota Policy: Quota policies allow you to constrain the resources used in your clusters, as aggregate quantities across specified namespaces, using pre-configured and custom templates. For more information, see Managing Resource Consumption in Your Clusters.
- Security Policy: Security policies allow you to manage the security context in which deployed pods operate in your clusters by imposing constraints on your clusters that define what pods can do and which resources they have access to. For more information, see Pod Security Management.
- Custom Policy: Custom policies allow you to implement additional business rules using templates that you define to enforce policies that are not already addressed using the other built-in policy types. For more information, see Creating Custom Policies.
NOTE: Not all policies described here are available in Tanzu Mission Control Essentials edition. For a comparison, see VMware Tanzu Mission Control Feature Comparison Chart.
Tanzu Mission Control Catalog
Clusters attached to Tanzu Mission Control can utilize the packages built into the service. Tanzu Mission Control’s catalog contains several tools platform operators commonly deploy to their clusters. Operators can deploy ingress controllers, certificate management tools, log processors, and monitoring solutions.

Tanzu Mission Control Design Recommendations
VMware recommends registering the Tanzu Kubernetes Grid Supervisor cluster as a management cluster in Tanzu Mission Control to provide a centralized portal for cluster lifecycle activities and policy enforcement within those clusters.
It is also recommended to attach any conformant Kubernetes clusters to Tanzu Mission Control to gain policy enforcement across platforms. Tanzu Mission Control can apply the same policy hierarchies and rules to any cluster managed by TMC, whether the cluster is on a VMware Cloud on AWS Tanzu Kubernetes cluster or an open-source Kubernetes cluster deployed on bare-metal servers.
Observability
It is sometimes difficult to know what sort of problems will arise within the applications being deployed within modern distributed systems. Observability is our ability to measure a system's state based on its generating data, such as logs and metrics. The sections below outline observability topics relating to Tanzu services on VMware Cloud on AWS.
Infrastructure Monitoring
Cloud administrators must still monitor their infrastructure even when running in a cloud environment. The cloud might make resources elastic but knowing where your environment has bottlenecks is still important and proper sizing of resources can limit cloud costs. Virtual machines, ESXi hosts, and Kubernetes clusters should have a system in place to monitor their performance over time. Performance data is useful for understanding the steady state of a system, alerting on changes to the steady state, and forecasting future sizing requirements.
Cloud administrators can use VMware vRealize Operations (vROps) Cloud to monitor and alert on both virtual machines and Kubernetes clusters running in VMware Cloud on AWS. vRealize Operations Cloud can be used to monitor VMware Cloud on AWS as well as on-premises VMware environments through a centralized portal.

Application Monitoring
The state of applications running in Tanzu Kubernetes clusters should also be visible to platform operators managing those clusters. Cloud administrators use vRealize Operations Cloud for monitoring capacity and health of the cloud and Kubernetes platform. Platform operators use the options in the sections below to visualize application and cluster metrics to determine the health of their services.
In VMware Cloud on AWS, there are two common solutions to visualizing application performance metrics within Tanzu Kubernetes clusters, both of which can easily be deployed through Tanzu Mission Control. Although these are not the only two ways of collecting performance metrics, they are the most common patterns within VMware Cloud on AWS.
Prometheus / Grafana
Prometheus is an open-source, community-driven Cloud Native Computing Foundation (CNCF) project commonly used to scrape and store metrics from applications and components within a Kubernetes cluster. Prometheus uses the Kubernetes API server and kube-state-metrics to obtain metrics about the Kubernetes nodes and the containers running within the cluster.
Grafana is a tool commonly used to display Prometheus metrics to administrators and SREs. Grafana is also an open-source solution used by DevOps engineers to seek information about what is happening with clusters and applications.

Prometheus and Grafana can be deployed together through a Tanzu Mission Control Package located in the TMC Catalog.
Tanzu Observability
Tanzu Observability is a VMware-based Software-as-a-Service (SaaS) solution that uses a collector running in a container to grab Kubernetes-based metrics from the API server, and Kubernetes kube-state metrics much like Prometheus does. This collector forwards the metrics to the Tanzu Observability public endpoint, where platform operators can see pre-built dashboards for the clusters and build new ones based on their requirements.

As a SaaS service, the solution scales to handle metrics from multiple sources, including Kubernetes clusters, without an administrator’s intervention, eliminating toil from the platform engineers’ tasks. Tanzu Observability can also ingest traces from tools using OpenTelemetry.
Performance Monitoring Design Decision
It’s essential to have a performance monitoring solution in place before workloads go into production so that you can have a baseline of their characteristics over time. Performance metrics are often the first line of defense for troubleshooting slow applications and should be considered a requirement for production workloads. Performance metrics combined with an alerting mechanism should be in place to respond quickly to undesired performance-related issues.
Both Prometheus/Grafana or Tanzu Observability can be used for performance monitoring and alerting needs. The decision to use these tools is usually identified by the differences between the products, found here:
Cost – Prometheus and Grafana are free tools that can be deployed through the Tanzu Mission Control Catalog or Tanzu Kubernetes Grid Packages, while Tanzu Observability is a paid Software-as-a-Services solution.
Scalability – Prometheus and Grafana work well to manage a single Kubernetes cluster. As the number of metric endpoints to scrape increases, the ability for Prometheus to scrape them all becomes more difficult. Tanzu Observability deploys a new collector to each cluster but forwards the metrics to a centralized, scalable solution, resolving this issue.
Aggregation – Due to scalability issues with Prometheus in multi-cluster environments, metrics may exist in separate Prometheus instances. Prometheus uses a project called Thanos to aggregate the individual Prometheus instances into a centralized portal. This Thanos instance will also require maintenance and upgrades, whereas Tanzu Observability already aggregates metrics from all collectors and displays them in the SaaS portal.
Logging
In addition to performance metrics, platform operators need logs to reveal events occurring in their Kubernetes platform. These logs can come in several types, including application and audit logs. These logs should be aggregated so that event correlation can occur between environmental issues and actions recently completed by administrators or automation routines. These logs are also required for many compliance reasons.
A version of vRealize Log Insight Cloud is included with a VMware Cloud on AWS subscription. Cloud administrators can retrieve audit and activity logs about the VMware Cloud on AWS environment through the vRealize Log Insight Cloud console. Platform operators can use this instance of vRealize Log Insight Cloud as a logging destination for the Kubernetes clusters and the applications within them.
Application Logging
Application logs are critical to the health and improvement of deployed applications. These logs can come in several forms, but one of the tenets of a twelve-factor app is that the application shouldn’t need to worry about log rotation and management. It’s therefore common to send application event streams to stdout.
In a Kubernetes cluster, containers are transient and are often restarted before an administrator can retrieve the logs. To ensure records are captured before failures occur, log collectors are used to gather these logs and forward them to an appropriate aggregation service in near real-time.
Auditing
When changes are applied to a system, they correlate with a difference in its behavior. Audit logging refers to logging the chronological record of events that affect the system. These events may be critical for security review and understanding what caused a system to change its behavior.
The Kubernetes API server records every interaction with an audit log. The audit logging capability is configurable using a policy file that controls which events should be recorded and what data they should include. Typically, each log entry contains what happened, when, and who was involved in the action.
Kubernetes Cluster Logging
Kubernetes components create their logs chronicling the activities taking place in the cluster. API server logs, controller logs, ETCD logs, and Kubelet logs are all components of the Kubernetes cluster. Platform operators should be alerted when abnormal behavior occurs, such as the eviction of nodes, loss of a cluster member, or expired certificates.
In Tanzu Kubernetes clusters, these control plane components are also running as containers, so these logs are retrieved along with the other applications running in the cluster.
Logging Design Recommendation
The Tanzu Mission Control catalog can deploy Fluent Bit, an open-source log processor tool that runs as a daemonset in your Tanzu Kubernetes clusters. Fluent Bit can be configured to capture the Kubernetes audit logs, application logs, and Kubernetes control plan logs from the Tanzu Kubernetes node where the daemonset runs. These logs can then be filtered or parsed by Fluent Bit before being sent to log aggregation and visualization tool like VMware vRealize Log Insight Cloud.

Installation Experience
To activate the Tanzu Kubernetes Grid service on VMware Cloud on AWS, cloud administrators must have first deployed their VMware Organization and an SDDC. The cloud admins will go on to activate the TKG service and create resource allocations in a vSphere Namespace.
TKG Activation
Cloud administrators can select an existing SDDC with sufficient capacity for running the Tanzu Supervisor Cluster. They will click the “Activate” option from the Actions drop-down in the Cloud Console.

A wizard-driven activation process requests network information for your Kubernetes environment. Four separate network CIDR ranges are needed to activate the TKG service.
NOTE: These network CIDRs are described in greater detail in the CIDR Sizing section of this document. After entering the networking information, the wizard will display a summary screen before confirming your intent to activate the Supervisor cluster.

Once the cloud admin has activated the Supervisor cluster, three Supervisor virtual machines are deployed within the SDDC. These Supervisor virtual machines can be found in the “Mgmt-ResourcePool” along with the vCenter Server and other objects managed by VMware. Within the vSphere vCenter Client, the Workload Management page will be available to start creating vSphere Namespaces.
vSphere Namespace Creation
Upon successful activation of the Tanzu Kubernetes Grid Service, cloud administrators can now create vSphere Namespaces. vSphere Namespaces allow cloud admins to assign a set of VMware Cloud resources to a group of users or team.

The following information is needed to configure a vSphere Namespace:
Permissions – Users and Groups identified through vSphere Single Sign-On that will have access to deploy or use clusters within the namespace.
Storage (Optional) – Define the VM Storage Policies that should be used for persistent volumes within Tanzu Kubernetes clusters within the namespace.
Capacity Limits (Optional) – Create limits on how many VMware Cloud on AWS resources the assigned users are allowed. Tanzu Kubernetes clusters must stay within this limit. Administrators may set limits on CPU, memory, disk, and disk by datastore.
VM Classes – Specify the size of the virtual machines that can be used to create Tanzu Kubernetes clusters.
Cloud administrators can give the Kubernetes Endpoint URL to Platform operators after creating the vSphere Namespace. This Endpoint URL contains instructions on setting up the Kubernetes CLI tools and how to authenticate to the namespace to build clusters.

Tanzu Kubernetes Cluster Deployment
Platform operators can use one of the methods in the sections below for the lifecycle management of TKCs.
Kubernetes CLI
Using the Kubectl and vSphere Plugin obtained through the vSphere Namespace endpoint, platform operators can use configuration files in a YAML format to deploy, upgrade, scale, and delete clusters. Organizations that use version control repositories to store infrastructure as code (IaC) should use the Kubernetes CLI for cluster lifecycle automation.
apiVersion: run.tanzu.vmware.com/v1alpha2
kind: TanzuKubernetesCluster
metadata:
name: string
namespace: string
spec:
topology:
controlPlane:
replicas: int32
vmClass: string
storageClass: string
volumes:
- name: string
mountPath: string
capacity:
storage: size in GiB
tkr:
reference:
name: string
nodeDrainTimeout: int64
nodePools:
- name: string
labels: map[string]string
taints:
- key: string
value: string
effect: string
timeAdded: time
replicas: int32
vmClass: string
storageClass: string
volumes:
- name: string
mountPath: string
capacity:
storage: size in GiB
tkr:
reference:
name: string
nodeDrainTimeout: int64
settings:
storage:
classes: [string]
defaultClass: string
network:
cni:
name: string
pods:
cidrBlocks: [string]
services:
cidrBlocks: [string]
serviceDomain: string
proxy:
httpProxy: string
httpsProxy: string
noProxy: [string]
trust:
additionalTrustedCAs:
- name: string
data: string
For more information, see the VMware Tanzu Kubernetes Grid Service documentation.
Tanzu Mission Control
VMware recommends registering the Tanzu Kubernetes Grid Supervisor Cluster as a management cluster within Tanzu Mission Control. See the official documentation for registering a Supervisor Cluster with Tanzu Mission Control for more information.
After registration is complete, platform operators can use the TMC console to deploy Kubernetes clusters from the UI or Tanzu CLI.

TKG Deactivation
If the Tanzu Kubernetes Grid service is no longer needed, cloud administrators can deactivate the service. To Deactivate the TKG Service, select the SDDC within the VMware Cloud Console, choose the Deactivate option from the drop-down.

Summary and Additional Resources
This deployment guide walks through the design decisions and steps required to successfully deploy Tanzu services into a VMware Cloud on AWS environment.
Additional Resources
- Tanzu services Announcement
- Tanzu services Technical Introduction
- VMware Cloud on AWS Product Documentation
- Helpful Blogs focused on Tanzu services on VMC
Changelog
The following updates were made to this guide.
|
Date |
Description of Changes |
|
3/29/2022 |
Initial Publication |
| 4/18/2022 | Namespace CIDRs require a /23 or better for Tanzu Actiavtion |
About the Author and Contributors
- Eric Shanks, Sr. Technical Marketing Architect - CIBG
- William Lam, Sr. Staff Solutions Architect - CIBG
- Blair Fritz, Sr. Product Line Manager - CIBG
- Nathan Thaler, Staff II Product Solutions Architect - CIBG