
Select and Design a Disaster Recovery Solution
Selecting the Solution
To replicate the data from one site to another, there are two solutions that are currently being used.
- Storage-based replication
- Hypervisor-based replication
Traditional recovery methods involved setting up two sites and enabling storage-based replication between these two sites. Replicating data was completely handled by the storage array. LUN created on the storage array was configured to be replicated over to the secondary site. During disaster recovery, a snapshot of the replicated LUN was created on the recovery site and mounted manually to use the data. This solution lacked automated recovery.
VMware Site Recovery Manager filled this gap of automated recovery with the storage array plugin. Not only the process of creating array snapshots and mounting them was automated, but this also provided additional granularity on the recovery of the virtual machine. You could now create protection groups to group dependent workloads, create a recovery plan, and set a priority order for recovery of workloads. However, what lacked was choosing to just replicate an individual VM over a complete LUN. Placement of VM on a particular LUN was to be designed based on the need for replication.
Storage-based replication also requires storage hardware on the production and recovery site. These requirements forced users to use one particular storage vendor in both sites along with an additional replication license which increased the overall cost for the DR solution.
VMware introduced Hypervisor/Host-based replication (HBR) to overcome the challenges of storage- based replication. With HBR, you can replicate the data of an individual virtual machine from one site to another. HBR provides the granularity and flexibility of enabling replication on individual virtual machines residing on any supported storage for the ESXi, which addressed the major challenge of the storage agnostic solution. For example, you may choose to have iSCSI or Fibre-attach storage with VMFS on the production site and choose an NFS or VSAN based solution on the recovery site.
The hypervisor at the production site where the virtual machine is running can perform the initial replication (first full copy) and also track the changes and replicate them over to the recovery site. This is done with the help of a paired replication appliance deployed on both sites. An HBR-enabled machine can also utilize virtualization features such a HA or vMotion.
Designing the Solution
When designing a recovery solution, there are multiple factors to be considered covering all the components of the datacenter.
Architecture
VMware Provides two offerings for Disaster recovery solution with VMC on AWS.
- Using VMware Site Recovery Manager: This is an on-demand DRaaS solution that is delivered with vSphere replication and VMware Site Recovery Manager. With this service, along with enabling the add on from the VMC on AWS UI, you deploy a vSphere appliance in your on-premises vSphere environment. You can then Pair sites and replicate your critical VMs running in the on-premises environment to an SDDC created on VMC on AWS.

- Using VMware Cloud Disaster Recovery : This is VMware's on-demand disaster recovery service that is delivered as an easy-to-use SaaS solution and offers cloud economics to help keep your disaster recovery costs under control. The target SDDC can be created immediately prior to performing a recovery and not upfront, while also supporting the replications in the steady state. The DRaaS connector is deployed as a virtual appliance that replicates the data to a Scale-Out Cloud File System (SCFS). This volume is mounted when we choose to perform a recovery as livemount on SDDC and since the VM are already in ESXi supported format recovery is handled at ease.
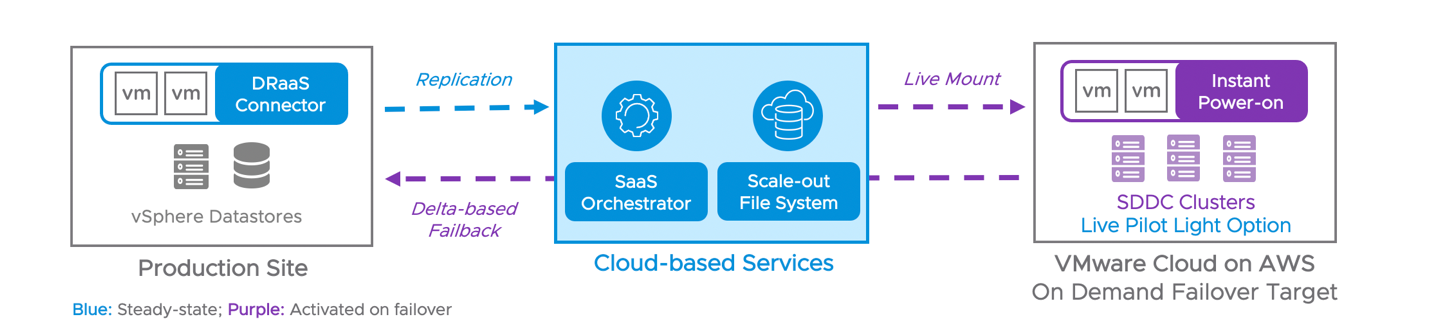
SDDC Planning
When you are selecting an SDDC as a recovery site, you must cover these major categories of an SDDC.
Sizing
- When sizing the DR site you must analyze the current infrastructure that is deployed and list all resources that need to be protected.
- When you have multiple on-prem datacenters, design the solution to either use one dedicated SDDC as a recovery site or plan to use in dual mode (each site as production and recovery site)
- Deployment Type
- Single Host SDDC
- On-demand (also known as "just-in-time")
- Pilot Light with cloud bursting
See the table below for detailed information:
|
Annual SDDC commitment |
Available with Solution |
SDDC startup time |
|
|
Single Host SDDC |
Single host SDDC deployed used for building and testing DR plans, after which the recovery SDDC can be deleted to save recurring costs. |
vCloud DR |
A single host SDDC does not provide any data protection does not offer production-level SLAs, and will automatically be torn down in 30 days. A single-host deployment should only be used for testing purposes and is not intended for production usage. |
|
On-demand |
Only when needed |
vCloud DR |
|
|
Pilot Light |
Minimum 3 VMware ESXI on cloud on AWS hosted at all times or 2 Host SDDC with a EC2 instance as Witness. |
vCloud DR with vSphere Replication and Site Recovery Manager |
|
Recovery Objectives Considerations
- Recovery Time Objective (RTO): The recovery time objective (RTO) is the targeted duration of time and a service level in which a business process must be restored as a result of an IT service or data loss issue, such as a natural disaster. RTO is one important category and the earlier table can be used to determine the offering to choose as a DR solution
- Recovery Point Objective: RPO defines the maximum acceptable age that the data stored and recovered in the replicated copy (replica) as a result of an IT service or data loss issue, such as a natural disaster, can have. The lower the RPO, the closer the replica's data is to the original. However, lower RPO requires more bandwidth between the source and target locations, and more storage capacity in the target location depending on the Point-in-time configured on VM.
- Point-in-Time Instance: You define multiple recovery points (point-in-time instances or PIT instances) for each virtual machine so that when a virtual machine has data corruption, data integrity, or host OS infections, administrators can recover and revert to a recovery point before the compromising issue occurred.
- Accounting for overhead using each datacenter in distributed mode:
- Include the snapshot and swap space
- Add vSphere Replication appliance overhead depending on the number of VM’s configured for replication
- Network Connectivity Considerations
- Replication Objectives like RTO and RPO configuration are dependent on network
- Network Compression
- ISP selection, network bandwidth, and redundancy
- IP migration if any (public IP)
- name record update
- Perform Inventory mapping
- VM resource pool and folder Inventory mapping
- Datastore mapping
- Network mapping
- Swap datastore configuration
Recovery Plan Considerations
The primary considerations for DR recovery plan are defined here. For planning information, refer to DR Planning document.
- Limits on recovery plans, protection groups, etc - Discuss how this affects the overall design and how to best optimize.
- Limits on concurrent recoveries to avoid burst mode- Discuss how this impacts DR events and offer strategies for prioritization of recoveries during a DR event.
- Restart Priority and Recovery Order
- Split-brain breaker(witness)
Configure Role and Permission for Recovery Management
- Consider roles and permission when a dedicated user is used to execute steps on the shared service during recovery. Example - update a DNS record during recovery.
- Manage how shared services such as DNS, DHCP, and domain authentication are handled
- Configure permission and roles for recovery management.