
Feature Brief: Auto Remediation
Introduction
One of the benefits of running your workloads in VMware Cloud on AWS is that VMware manages the platform, including all of the infrastructure and management components. VMware also performs regular updates across the SDDC fleet to deliver new features, bug fixes, and software upgrades.
Operationalizing common tasks for these components is crucial. The Autoscaler Service within the platform helps with this. Autoscaler consists of three primary functions:
- Auto Remediation: Replace problematic infrastructure based on virtual infrastructure events.
- Planned Maintenance: Replace Amazon EC2 instances and vSAN witness virtual machines (VMs) that are scheduled for retirement.
- Dynamic Scalability: Scale the SDDC up or down dynamically based on resource usage.
The goal is to ensure your SDDC is truly elastic and self-healing without impacting the hosted workloads.
Continuous monitoring and validation
The three primary functions above can be carried out because we monitor the health of various SDDC components and services all the time. When an event occurs, it is forwarded to the Autoscaler, which reacts very quickly to validate and execute a remediation plan based on the type of event.
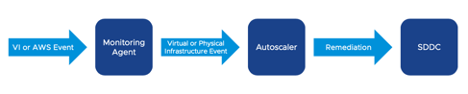
Prior to executing the remediation plan, the service will validate the condition. This is useful in the event of a transient error – for example, a minor network glitch may fire a false positive. If an event is thrown stating that a host is disconnected from vCenter, when in reality it is connected and healthy, further validation would ignore the event instead of attempting to remediate.
If the event is validated and identified as a real failure, we can now execute our remediation plan.
Remediation in the event of a failure
Let’s look at a host failure example. Whether on-premises or in the cloud, components within a host can and will fail.
Sometimes, it’s a minor issue – such that the host is running, but in a degraded state. This could be a redundant component like a fan or power supply, or even a single memory module. Other times, the component failure could be catastrophic – such as a processor or system board. In this case, Autoscaler receives the event, validates it, and then springs into action.
A key advantage of VMware Cloud on AWS is that we always have access to a fleet of hardware. This allows us to provision and add a host immediately to the cluster to ensure there is enough compute and storage capacity to perform VM migrations or an HA reboot if necessary. If a non-transient event occurs, a host is provisioned and added to the cluster before remediation action continues.
It’s important to note that you would never be charged for the addition of a host during auto remediation processes. The only time you would be charged for a host is in the event of an Elastic DRS (EDRS) scale-up due to storage or compute restraints from customer workloads.
Sample remediation plans
Let’s look at some high-level examples of what remediation plans might include:
- IF host experienced PSOD, THEN collect EBS snapshot and reboot host
- IF host is still not healthy, THEN remove and re-sync vSAN data to new host
- IF vSAN is not healthy, THEN soft reboot host and trigger vSAN repair
- IF host has history of multiple failures, THEN remove and re-sync vSAN data to new host
Of course, these are high level examples, and the workflows can range from very simple to complex in an effort to maintain SDDC availability.

As mentioned above, remediation steps only occur after an additional host has been successfully added to the cluster. Once remediation has been performed – and if the failure in the original host was able to be resolved and health checks are passed – the newly added host will be placed in maintenance mode and removed from inventory.
However, if the failed host could not be recovered, then it will be removed and the newly added host will now remain in the cluster. Once a failed host is removed from the cluster, it is returned to the fleet for AWS to repair.
Building a truly resilient SDDC
While the above example referenced a host hardware/component failure, Autoscaler will also address software failures such as PSODs, vCenter, vSAN, FDM, and so on.
It’s all about giving you access to the services and workflows that enable your SDDC to be truly resilient and highly available.