
Automating SDDC Cluster Lifecycle with DCLI
Introduction
VMware Cloud on AWS has the ability to add new clusters to an existing SDDC. This is most useful for workload separation. A cluster could be specified as the failover resource, a development environment, and so forth. Second, these clusters can be deployed with a specific amount of CPU cores. This control is certainly important when it comes to running mission-critical applications that happen to be licensed per-core. Even better, it is extremely easy to automate the lifecycle of a cluster with Datacenter CLI (DCLI).
Let’s check out some examples of how we can manage clusters within VMware Cloud on AWS.
Environment Setup
As part of this blog, I will be using a previously deployed SDDC and will be using the ‘filter’ parameter of DCLI heavily. Therefore, while we always encourage you to be on the latest version of DCLI, you will need DCLI 2.10.2 or better. We will start by opening a terminal session and authenticating to the VMware Cloud on AWS service with our API Token. Then, we need to identify a couple services to use. These services will be the following:
- com vmware vmc orgs
- com vmware vmc orgs sddcs
- com vmware vmc orgs sddcs clusters
- com vmware vmc orgs tasks
One last setup requirement, we will need to grab IDs for the Organization and SDDC which we’ll be working with.
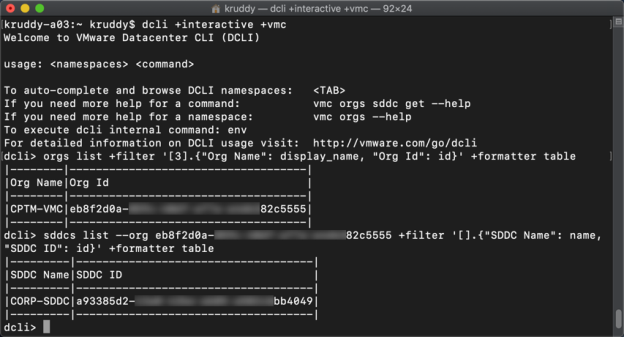
We can summarize the above criteria with the following code:
|
1 2 3 4 5 6 |
# Connect to the VMware Cloud on AWS Service dcli +interactive +vmc # Reference Orgs service and display ID of the desired Org orgs list +filter '[0].{"Org Name": display_name, "Org Id": id}' +formatter table # Reference Sddcs service and display ID of the desired SDDC sddcs list --org xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx +filter '[].{"SDDC Name": name, "SDDC ID": id}' +formatter table |
Cluster Creation – Interactive
The first example we’ll take a look at is using DCLI’s interactive mode to create a new cluster. To do this, while in the DCLI terminal, we can use DCLI’s convenient tab-complete option to help figure out how to make the command. First, enter ‘sddcs clusters’ and we will see there are two available options to complete the command: create and delete. We can then see the required and optional parameters for our ‘create’ method by entering the following command: sddcs clusters create
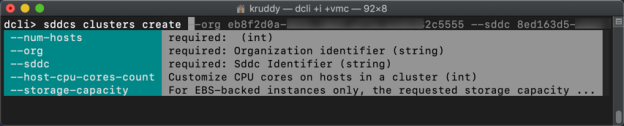
The first three parameters are the most important ones and are required. The only parameter we are not yet familiar with, num-hosts. This is an integer based parameter used to tell VMware Cloud on AWS how many hosts we want the new cluster to be deployed with. We can also use the host-cpu-cores-count parameter to specify the CPU cores the hosts in this new cluster should have available. The other available parameter is storage-capacity and is only used in conjunction with EBS.
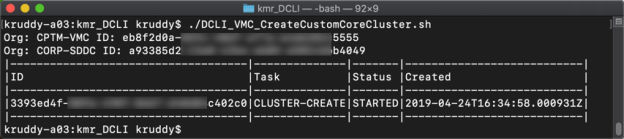
Creating a new cluster containing one host with only 8 CPU Cores available will look something like the following command:
|
1 2 |
sddcs clusters create --org xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --sddc xxxxxxxx-xxxx- xxxx-xxxx-xxxxxxxxxxxx --num-hosts 1 --host-cpu-cores-count 8 +filter '{ID: id, Task: task_type, Status: status, Created: created}' +formatter table |
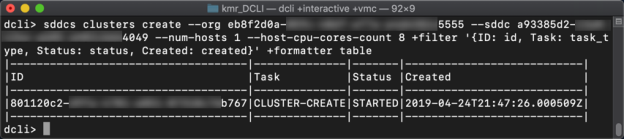
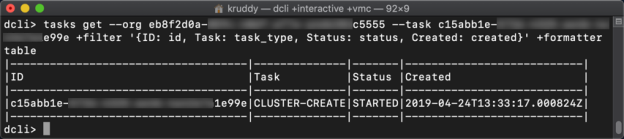
The response from the above command is a task object, which we have used the filter parameter to return back some basic information. The returned object is a task because it will a little bit of time to create the cluster, deploy the host/s, and configure the cluster. We can follow along with the task using the tasks service, as follows:
|
1 |
tasks get --org xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --task xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx +filter '{ID: id, Task: task_type, Status: status, Created: created}' +formatter table |
Cluster Creation – Scripted
For this example, we will be creating another cluster by taking the commands from our prior section and creating a script compatible with DCLI’s scripted mode. Instead of copy/pasting each of the IDs into our script, we will use the filter parameter to populate a couple parameters and also output some basic information as the script runs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Set details for new cluster NUM_HOSTS=1 HOST_CPU_CORES_COUNT=8
# Deployment Code # Get ORG Information ORGID=$(dcli +vmc com vmware vmc orgs list +filter '[0].id') ORGNAME=$(dcli +vmc com vmware vmc orgs list +filter '[0].display_name') Echo "Org:" $ORGNAME "ID:" $ORGID
# Get SDDC Information SDDCID=$(dcli +vmc com vmware vmc orgs sddcs list --org $ORGID +filter '[0].id') SDDCNAME=$(dcli +vmc com vmware vmc orgs sddcs list --org $ORGID +filter '[0].name') Echo "Org:" $SDDCNAME "ID:" $SDDCID
# Create the New Cluster in the SDDC dcli +vmc com vmware vmc orgs sddcs clusters create --org $ORGID --sddc $SDDCID --num-hosts $NUM_HOSTS --host-cpu-cores-count $HOST_CPU_CORES_COUNT |
Cluster Information
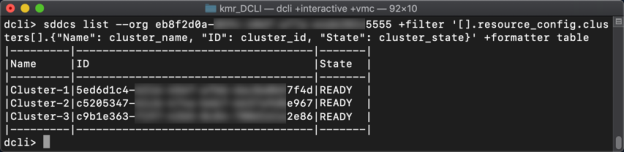
We have deployed two new clusters, making a total of three clusters available in our SDDC. This example will take a look at how we can retreive information about those clusters. Remembering back to the first section, there were only methods available for create and remove. This is because the clusters are available as part of the SDDC object as the “clusters” property. We can retrieve some basic information about our clusters with the following command:
|
1 2 |
sddcs list --org xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx +filter '[].resource_config.clus ters[].{"Name": cluster_name, "ID": cluster_id, "State": cluster_state}' +formatter table |
Cluster Removal
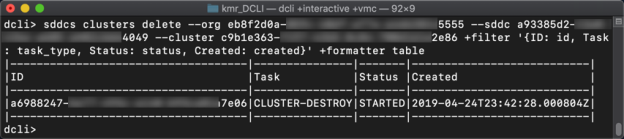
The last example will complete the lifecycle management of our SDDC’s cluster, and that task is the removal of the cluster. The ‘delete’ method has three parameters, all of which are required. At this point, the first two can be assumed to be Org and SDDC IDs. The third is the Cluster ID, which we can reference from the prior section.
Removing a cluster from an SDDC will look something like the following command:
|
1 |
sddcs clusters delete --org xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --sddc xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --cluster xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx +filter '{ID: id, Task: task_type, Status: status, Created: created}' +formatter table |
Summary
VMware Cloud on AWS based SDDCs can contain multiple clusters, which is beneficial for a couple reasons. First, workload separation. A cluster could be specified as the failover resource, a development environment, and more. Second, these clusters can be deployed with a specific amount of CPU cores. This control is certainly important when it comes to running mission-critical applications that happen to be licensed per-core. This article walked us through how to deploy new clusters, identify the deployed clusters, and remove clusters which are no longer needed.